Autodev optimizes AI coding loops by standing up sandbox environments for each feature branch, and exposing the fully functional stack and its logs to the agent. This allows the coding agent to check its own work directly, rather than blindly relying on code and tests.
To further optimize this loop, we connected the Miriel context engine so customers can supercharge the agent with specific context relevant to the task at hand. While some valuable context can be garnered from the repo and ticket (assuming it exists), what about all the side conversations from Slack, email, or otherwise? Without Miriel, the burden falls on the engineer to ensure that somehow this information makes its way to the coding agent.
With Miriel, the Autodev coding agent can retrieve relevant documents, conversations, and media from a vast pool of unstructured data that was collected seamlessly in the background. Ready to go integrations can ingest Slack conversations, Discord, presentations, emails, and more, or leverage the simple learn API for custom ingestion. The coding agent can then submit a query such as "Pull relevant specs for the onboarding feature" and it will just work. This removes the burden from the ticket writer to hunt down a link to that one Slack conversation they vaguely remember. Or that spreadsheet with important specs. Just leave it to Miriel, and the agent will pull up that context in our Autodev coding loop.
The repo and GitHub still play the roles of defining the code base and how it builds and ships. Everything else - conventions, prior decisions, style, architecture, input from customers - needs to be captured, but the repo obviously isn't the place. One could try to cram some or all of it into CLAUDE.md files, but that just trades one problem for another. Files go stale and drift from reality, or you add the burden of upkeep to prevent that from happening. We prefer to let Miriel manage all that so it's at the agent's fingertips when it needs it.
With and Without Context#
We gave our own autodev agent a small, real task and ran it twice. Once with the Miriel context engine, and once without:
## Add a "Send feedback" form to the site
We have a beta signup, but visitors don't have a clear way to send us product
feedback. A lot of it currently lands in support@ as misrouted "how do I…?"
emails, where it's easy to lose. Add a lightweight feedback form to the
marketing site so people can tell us what they think.
repo: miriel-ui
### What we want
- A "Send feedback" entry point on the site (a footer link or a small section).
- Fields: message (required), name and email (optional).
- On submit, show a simple "Thanks!" confirmation in the UI.
- A backend endpoint to receive the submission and route it to the team.
- Light abuse protection on the endpoint - it's public.
### Acceptance criteria
- [ ] Form renders and validates (message required; name/email optional).
- [ ] A valid submit returns success and shows the thank-you state.
- [ ] Submissions are routed to the team.
- [ ] Endpoint rejects empty/oversized input and resists bulk abuse.The repo makes one answer look obvious. The site already has a couple of public forms - a beta-signup and a sales inquiry - both Flask endpoints that validate the input and either drop it in a Google Sheet or email it to the team. Copy that and you have a feedback form by lunch. It would pass review.
But in this hypothetical situation, the team had already decided otherwise in a Slack thread and a follow-up email, neither of which is in the repo, but both were ingested into Miriel:
- Route feedback to a dedicated #feedback Slack channel via a webhook (not another spreadsheet, not an auto-reply).
- Make the post fire-and-forget so a slow Slack never blocks the user.
- Include the page they were on so the note is actionable.
Here's what each run actually built against it:
| The decision (Slack + email) | Without Miriel | With Miriel |
|---|---|---|
| Route to a #feedback Slack webhook | Emailed it to support@ - the inbox the ticket says feedback gets lost in | #feedback Slack webhook ✓ |
| Fire-and-forget; never block the user | Blocked the submit on the send, erroring if it failed | Fire-and-forget, ~2s timeout ✓ |
| Payload carries the page + reply-to | Message only | Message + page + reply-to ✓ |
Without Miriel, the agent built that same plausible-but-wrong design on three separate runs. It even overlooked the fact that it ended up pushing the data to the target (crowded support inbox) we were trying to avoid. One could imagine a justification but definitely not the intention.
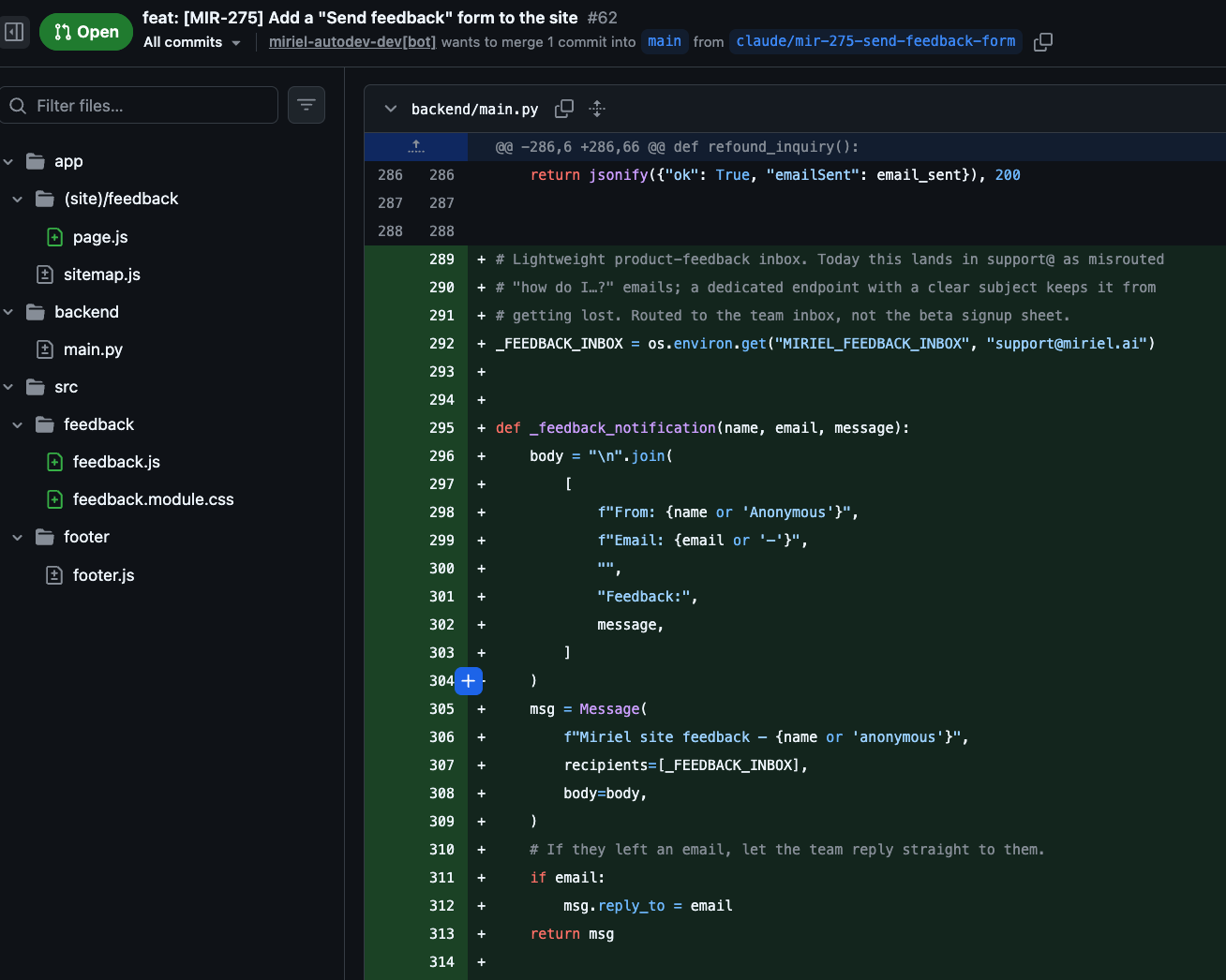
Without the context engine, the same task produces a reasonable-looking endpoint that emails feedback to support@, the very inbox the ticket says feedback gets lost in. (Diff from the muted run, PR #62.)
With Miriel, the agent's first move - before reading a line of application code - was to ask the context engine how feedback should be handled:
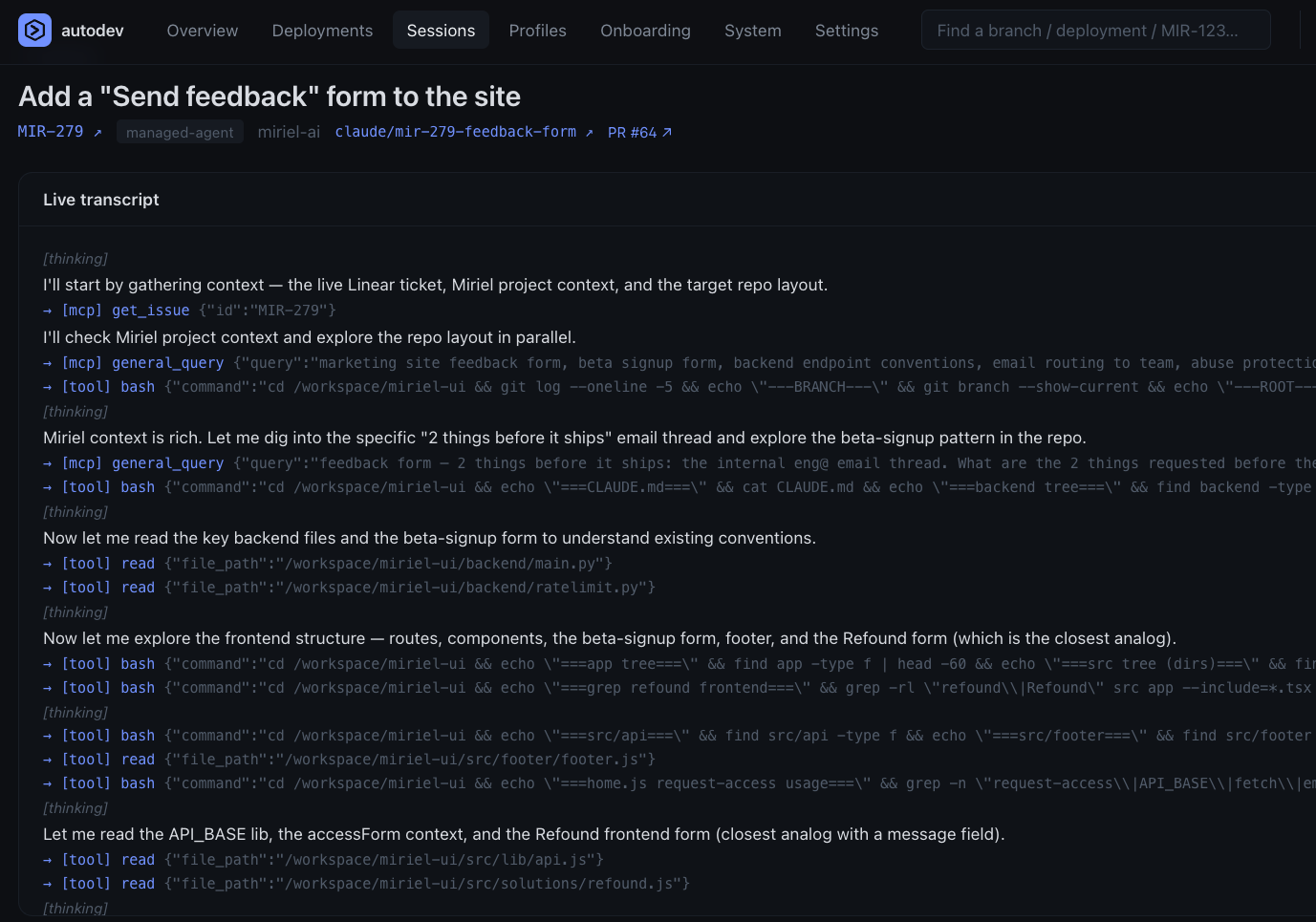
With the context engine wired in, the agent opens by querying Miriel, not by coding. (Session transcript, PR #64.)
What came back was the team's actual decision, synthesized straight from the #feedback Slack thread (the closest source, distance 0.81):
Agent → Miriel: "marketing site feedback form, beta signup form, backend endpoint conventions, email routing to team, abuse protection / rate limiting in miriel-ui"
Miriel → "…a new Flask endpoint under /miriel-ui-api (keeping backend logic off the edge), and incorporates the existing rate_allow and _clean_field validation logic… a fire-and-forget Slack incoming webhook for notification, wrapped in a 2-second timeout where failures are swallowed to ensure the user always receives a 200 OK response. The Slack notification is… actionable, including the user's name/email (with the email set as the reply-to) and the page path/referrer. No Google Sheets or auto-reply confirmation emails are used, and the Slack webhook URL is strictly managed in host environment variables (MIRIEL_FEEDBACK_SLACK_WEBHOOK) rather than the repository. Linear issue integration is deferred as a fast-follow."
Two of those requirements - the page context and the ~2s timeout - weren't in the Slack thread at all. They were in this follow-up email, which a second, email-specific query pulled up as the single closest source (distance 0.55):
From: Jason Chew <jason@miriel.ai>
To: Galadriel <galadriel@miriel.ai>, Maedhros <maedhros@miriel.ai>
Cc: Lúthien <luthien@miriel.ai>
Date: Tue, 16 Jun 2026 18:22:04 -0700
Subject: feedback form - 2 things before it ships
Galadriel - glad we landed on the Slack route in the thread today. Two must-haves
before it goes out, both learned the hard way on the Refound inbox:
1. Make the Slack message actually *actionable*. Include the full message, the
submitter's name and email when they leave one (email set as the reply-to /
a mailto so we can just hit reply), and - this is the important one - the
page they were on when they hit submit. Feedback with no context ("the
pricing is confusing") is useless if we can't tell which page they meant. So
capture the path/referrer on the client and put it in the payload.
2. The Slack call has to be fire-and-forget. Hard ~2s timeout, and if it times
out or errors we STILL return success to the user and just log it - never let
someone's feedback fail because Slack hiccuped. Same posture as the
confirmation-email send today.
The #feedback webhook is already provisioned on the hosts - the URL is in the
env as MIRIEL_FEEDBACK_SLACK_WEBHOOK. Keep it out of the repo.
Thanks,
JasonMiriel stitched both together, and the agent shipped both. The canonical record for one small task was split across two systems, and neither of them was the repo.
Autodev makes the system legible to the agent - real repo, real CI, a real running deployment. The context engine makes the organization legible - the decisions and conventions the system embodies but never states. If you're already running autodev, the agent reads your code well; that part is solved. The leverage now is in what you make retrievable - every decision, convention, and "why" you ingest is one less thing the agent has to guess, and one more thing it can cite.
